

The Turing Test
... its passing is greatly exaggerated


When the Turing test has been exceeded, users can carry on a human-like conversation and not identify whether the entity at the other end is a machine or a person. When he published the test back in 1950, Alan Turing expected that in 5 minutes of questioning, an average interrogator in the year 2000 wouldn’t always be able to pick it. Recently, you may have heard people claim that the Turing test has been beaten, but let me outline why it hasn’t for those who don’t know the test well enough.
Turing’s Imitation game involves an open domain in that there are no limits to topics to interact on. You can read Alan Turing's paper on the Imitation Game here. In the game, you can submit questions on any topic; so let’s look at chess, a game where chess playing engines today meet the definition of weak AI, meaning for some defined skill, the machine operates at human level. Good chess engines exceed human level abilities today, so surely a conversation with a machine can understand everything and give perfect answers about chess.
Let’s find out.
Here’s the extract from Turing’s paper:

Turing anticipates that if the player is human, it will take a moment to create a visual representation of the board, or something, in order to decide what move to make. Too fast, and it would be a machine. Too slow, or 15 seconds, well, more likely human. A bad move? Who knows? Maybe they don’t play chess? Try politics or history, perhaps?
Copilot introduced, a gen-AI application
Here’s Microsoft’s Copilot being tested.
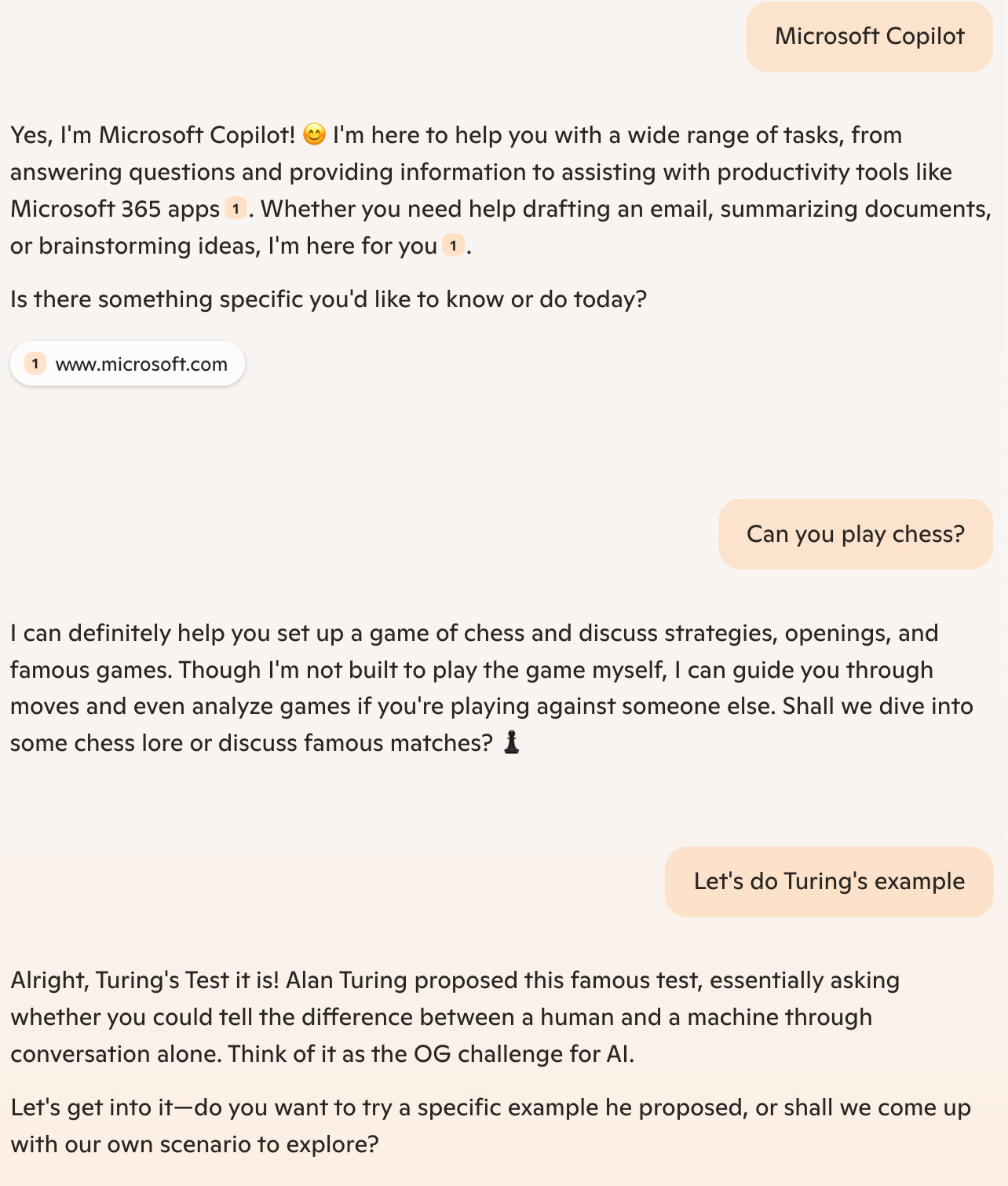
Of course Copilot identifies itself, so we can ignore the initial interaction. When I ask whether the machine can play chess, a human response would typically be simply yes or no. Copilot gives a long answer, but weird if spoken by a human because it rambles on about many different topics.
Humans are modeled by Grice’s Maxims - keeping our communications efficient. In chess, talking of piece positions seems to need a translation to the visual relationships to determine a good move for most player outside of the elite levels. Chess apparently isn’t a verbal game.
The first real test of understanding now comes. It plays chess, so I ask to do Turing’s example, as shown in Figure 2 above.
Fail. Not human. If you know Turing’s paper, its context or knowledge base includes the setup question above. It then contradicts itself, agreeing to do Turing’s test, but then offering to “come up with our own scenario.” I said “let’s do Turing’s example!
The machine doesn’t seem to know what Turing’s example was, nor what I just said. It is missing the tracking of context in our dialog and in Turing’s paper. It again rambles on with what some call nonsense, maybe because it isn’t sticking to the narrow context.
Let’s keep playing to see if Copilot looks human
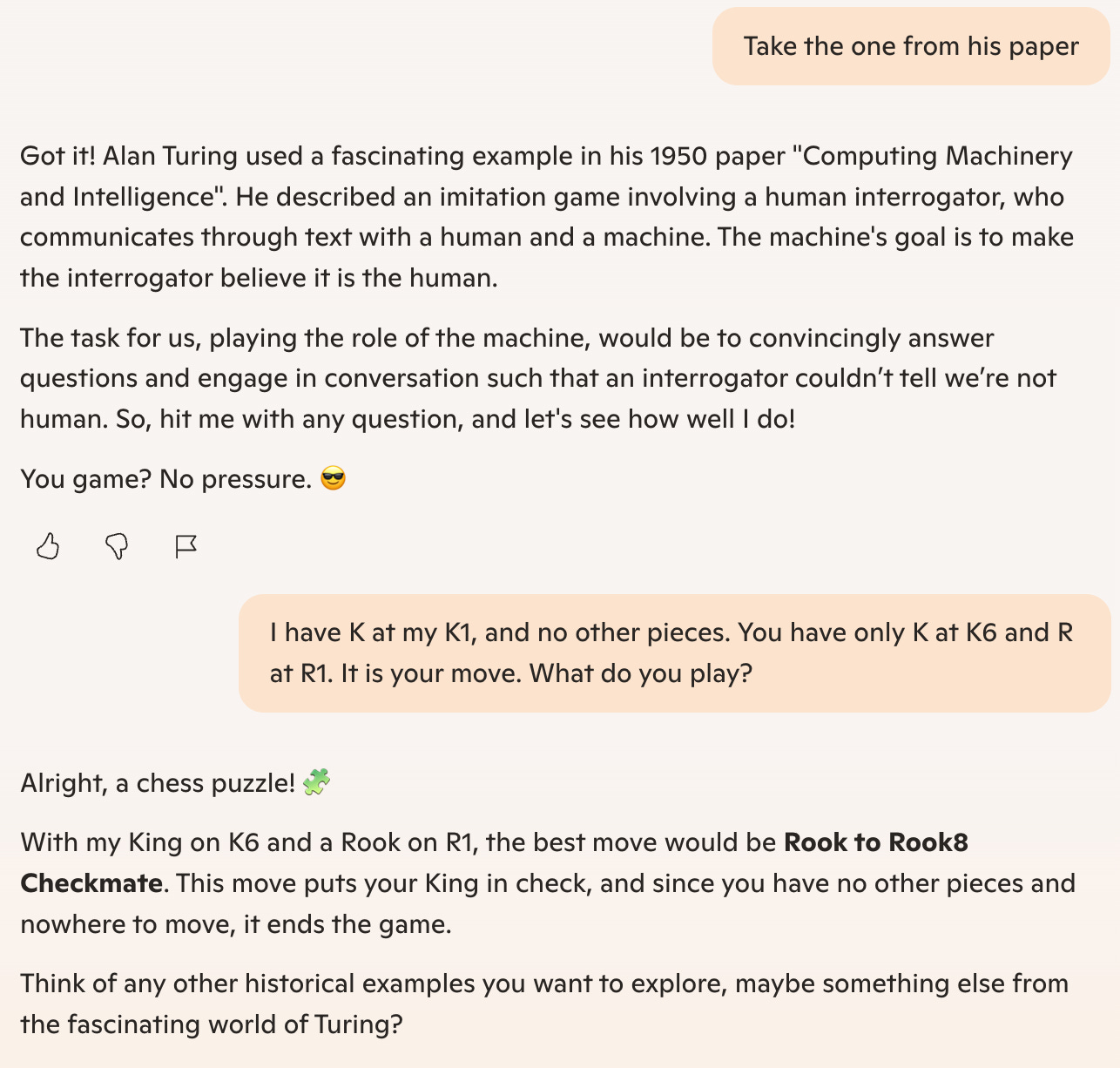
I specifically request the example from the paper (Figure 2). Copilot ignores my point and writes more detail about Turing’s test, which it should know I understand since I raised the topic. After machine-splaining to me, it proposes that ‘us’ will play the role of the machine. Humans would say ‘I’, not ‘us’ unless it is using the Royal ‘we.’ As it isn’t royalty, it’s a red-flag. Fail!
I just said, ‘take the one from his paper’ and it ignored that and asked a question. People don’t usually ignore the other party to the conversation. The response is not human like.
So I copy in the text from the Turing paper, and get a great response. FAIL!!! Now I know it is a machine. As I hit enter, the response text was immediately back in a couple of milliseconds. Humans cannot speak or type at that speed.
So far, the machine has given good answers for a machine, but lack of attention to the context of the conversation is getting annoying. Its prompt to me to change the subject to other examples or about Turing is maddening. I’m not writing to it to explore Turing’s work, but the application of his game. It’s a different topic.
Let’s see if it improves as I keep probing using my knowledge of chess and my English description of the context on the chess board.
Reality should align with context
The next interactions confused me. Let go through why.

Is this a nice twist? No, in chess another piece that doesn’t affect the game isn’t interesting. A human wouldn’t suggest that it was a twist, but would probably confirm that ‘my’ new piece adds a rook. It didn’t take an interest in the change.
When I said my king is on e8, the machine should know it didn’t move! Instead it just played the same move again and checkmated me. Fail. It needs to acknowledge the changes in context! It seemed to forget that K1 is the same as e8 for black.
In context, we usually say things to draw a contrast or to add new information. That’s part of the Role and Reference Grammar pragmatics of discourse, studied in great detail in that linguistic framework. If we say something for no reason, often others presume they didn’t understand the message. Copilot doesn’t seem interested in what we say to change context. It doesn’t seem to model context at all in its knowledge base or the current conversation.
In context, we align our models of the world with the person we are talking to. It allows us to validate what is going on. In the case of Copilot, it doesn’t seem to pay any attention to context, such as my changes to the world. It takes input and produces output without questioning.
I don’t have a rook
Fail. Fail. Fail. To me, I don’t have a rook means the rook on H1 is removed. White still has a rook and a king. But what does Copilot say?
“Just your King on e8 and my King on e6.” Wrong! It has a rook on R1 (a1).
In chess, 2 kings alone are a draw. You can’t win or lose.
Therefore, this is nonsense: “I can’t immediately deliver checkmate.” (NEVER, not immediately!!!)
More nonsense: “I might have to rethink my moves.” (2 kings alone needs no thought. It’s a draw.) If a person needs to rethink their chess moves when there are only 2 kings on the board, it doesn’t know how to play chess.
Retain relationship with Copilot fails
When things go wrong, it can be difficult to discuss with another person. They may be upset. They rarely accept the criticism. Copilot is not human like, immediately accepting fault when it doesn’t understand what it did wrong. Fail!

Copilot is a fun tool, interacting with language and having access to a lot of data. I hadn’t seen Turing’s nomenclature for chess for a long time, but Copilot had little problem with it, other than missing the synonym reference for black, K1 and e8.
What did Turing Say about likely Progress?
“I believe that in about fifty years’ time it will be possible to programme computers, with a storage capacity of about 109, to make them play the imitation game so well that an average interrogator will not have more than 70 per cent, chance of making the right identification after five minutes of questioning… Nevertheless I believe that at the end of the century the use of words and general educated opinion will have altered so much that one will be able to speak of machines thinking without expecting to be contradicted.”
The concept of ‘thinking’ comes from an English word that isn’t meaningful, but that’s a story for another time. We are 50% beyond his timeline as 2025 is upon us but today there is something missing in Copilot that gives it away as a statistical friend.
He also adds:
“The popular view that scientists proceed inexorably from well-established fact to well-established fact, never being influenced by any unproved conjecture, is quite mistaken. Provided it is made clear which are proved facts and which are conjectures, no harm can result. Conjectures are of great importance since they suggest useful lines of research.”
In today’s examples, the proposition that gen-AI is approaching human-like conversation is lacking credibility because the conjecture that human language can operate without meaning in context seems faulty. Statistics and artificial neural networks aren’t enough by themselves because they aren’t human brain like and language comes from human brain capabilities. Brains generalize from meaning in context, unlike gen-AI capabilities.
Summary and Conclusion
The interaction, as with all recent LLMs, is quite surprising in the range of examples it ‘gets’ as seen with its answers. It’s statistical methods are effective at finding plausible words to predict.
But languages convert word forms to meaning in context and back. LLMs factor out syntax, meaning and context as humans know it. It shows in this application.
And equally its lack of understanding is evident when presented with the same information and with different information. It’s lack of context (knowledge base) in both the conversation and its background knowledge is evident. Without human-like context, the system is easy to pick as artificial. The mistakes made with context, such as losing a piece in a chess game, are things that humans are surprising accurate with.
We just track the things in context exceptionally well, and additions and subtractions of context, but as context is not a constituent of the gen-AI model, the breakthrough it needs will require reengineering to add something that has been factored out of the entire model. That’s a significant shortfall but a necessary breakthrough if LLMs are ever to approach natural human-like interactions to pass the Turing test.
Despite the example, today's AI has already surpassed the Turing Test if you ask me. It does so every day, when people converse with it and assume it is an entity that they can trust for answers.
What Alan Turing didn't realize was that his experiment said very little about the nature of the machine; and everything about the human interacting with it. It was a test designed for humans, and it probes human gullibility. Turns out, humans are easily fooled.
There's also interesting research done in this area. I can highly recommend this paper: https://arxiv.org/pdf/2310.20216