

What's wrong with JUST generating text?
a killer app needs MEANING, too

The popular generative AI model is having some problems, as outlined by Gary Marcus in his article here. The headlines to take away are that generative AI has no killer ‘digital agent’ app, boneheaded errors remain and hallucinations remain. Text without trust may be creative, but that lack of trust is the key reason gen-AI will be replaced with something better for the language-based, multi-modal interface.
The killer ‘digital agent’ app will come from Natural Language Understanding (NLU) plus generation (NLG), rather than Large Language Models (LLMs).

A quick walk through
Here’s an interaction using Microsoft’s Bing just now to illustrate the limitations of gen-AI, contrasted with NLU.
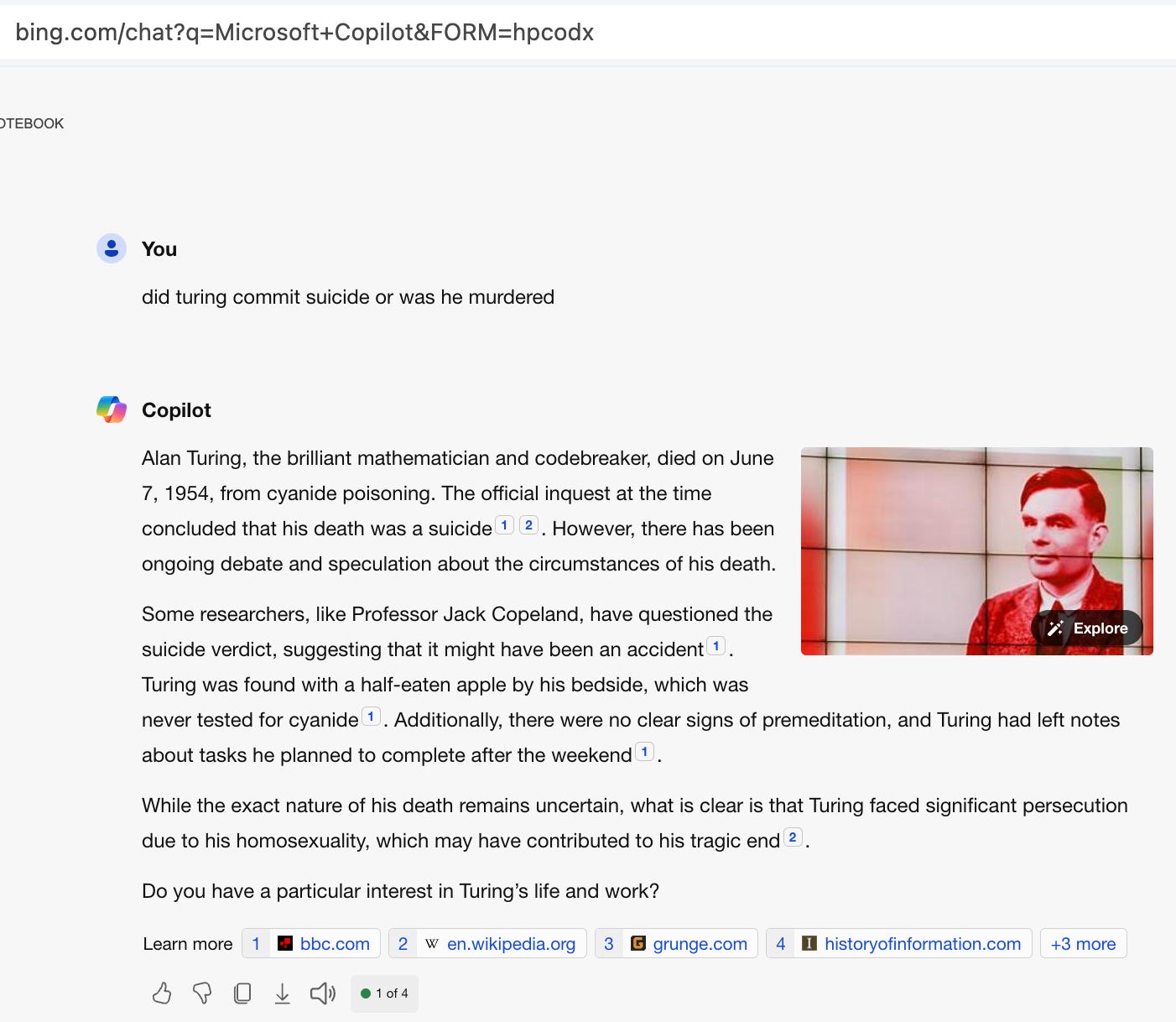
Is this the right answer?
In the human world, we would probably need to clarify what is meant before giving an answer. The name, ‘turing,’ could mean the great mathematician and theoretical computer designer, or it could mean one of potentially millions of others from his family or who share his name. If I chose a more common name, like ‘smith’, the answer should equally be clarified first.
In linguistics, the clarification of ‘referents’ is a part of discourse pragmatics that validates that we are on track with the same referent. It’s easy: “Turing-who?” or “Alan Turing?”
Let’s move on to the answer, and leave aside why it guessed who I was asking about.
LLM Limitation
The limitation in the rest of the answer would be addressed if the developer got, in addition to the text, its meaning!
In this example, there is a LOT of text returned. You can imagine a use-case where just the answers are ideal, but here we would need to weed through the date he died, his full name, the fact of speculation of his death, the circumstantial evidence, and so on.
I’ve asked a polar (yes/no) question, and the best answer is probably, ‘I don’t know.’ Some claim he was murdered, some suggest an accident and some say suicide. In the answer above, the murder response is missing. The LLM trouble, that is surfaced here, is that copilot mentions it sometimes, but it didn’t this time. That’s not deterministic, and often not good if some corporate environment demands precision in response.
If my killer ‘digital agent’ app were some kind of corporate bot, you can imagine that the answer to my question could be extracted from the text returned, but that would be a problem of the same scale as the initial question! It begs for NLU! And the form to return to the developer could be some kind of labelled response, like a named entity form (NER), but what is the representation for ‘it could have been an accident?’
A killer ‘digital agent’ app should not only provide the meaning of the responses, but also a tool to generate that into a sentence in a selected target language. Not everyone wants to generate a representation of meaning into a language, but the developers I have met who are involved in bot creation want to control the bot’s response.
My reason for proposing the solutiozn is that it is the one my company created, but the point here is to explain what is involved in a more useful app. Future ‘digital agents’ will use meaning, rather than raw text, for that additional control desired.
Future multi-modal interactions with language will be driven from new science, to enable engineering, since it is sufficiently complex to warrant detailed analysis.
Just extract text for the correct answer
In terms of the made-up responses that are untrue (again, hallucinations), it is often suggested that systems simply need to extract text correctly from training data or some reference files.
That may work for many use-cases, such as where the comparison files are at some high level of trust, but in the real world, context allows for contradictions. As a result, systems like LLMs that are trained on massive and general data cannot reliably answer questions without adding context. Somewhere in the text of the internet, we see “Turing was murdered” and “Turing died of natural causes (maybe referencing his mother)” and “Turing committed suicide” and “Turing accidentally bit a poisoned apple and died.” Putting this contradictory information all together is a stated goal of NLU: machine reading comprehension.
The ideal analysis would look at each of those sentences and provide an answer in context that forms part of a representation to send through a programmed bot’s mechanism.
As they say, NLU is hard. But quite solvable with new symbolics systems, such as with the Deep Symbolics model whose foundation is theoretical brain science: Patom theory. It’s the future.